背景介绍
机器翻译在神经网络之后得到了长足的发展。随着国际化的趋势,机器翻译在加强国际交流中的作用日益明显。本文将介绍一下基于最新的神经网络翻译架构Transformer来完成双语翻译。
Transformer架构
结构图
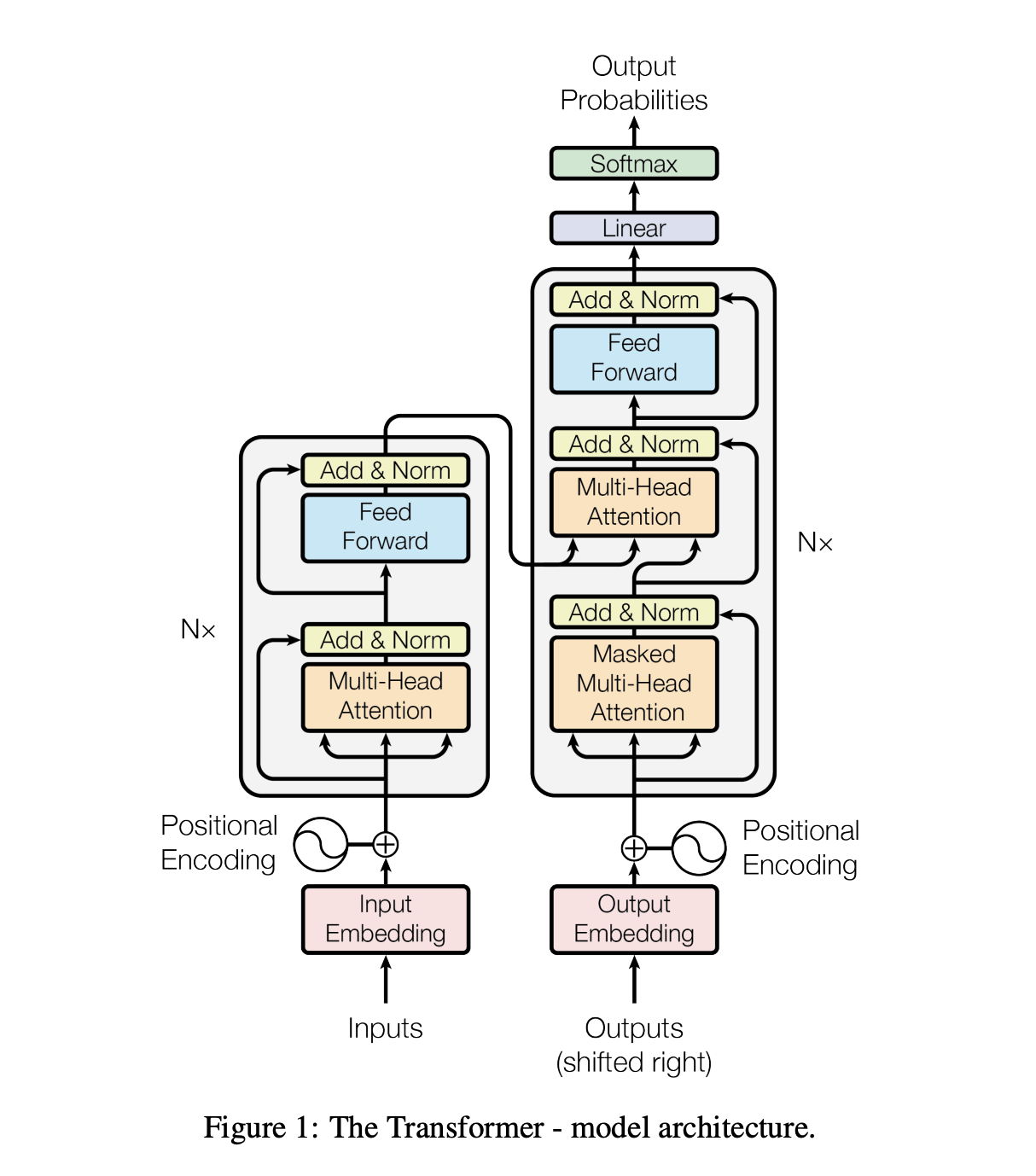
Transformer架构图如下,总体可以分为两部分,编码器和解码器(Encoder和Decoder)。编码器和解码器分别有两种基本单元堆叠而成。基本单元又主要分为两种模块,Multi-Head Attention和Feed Forward Network。
###Multi-Head Attention
首先说一下Attention,可以简单用下面一个公式说明白:
$$
Attention(Q,K,V) = softmax(\frac{QK^T}{\sqrt{d_k}})V
$$
这边采用$\sqrt{d_k}$进行缩放,因为当两个纬度增加时,向量的点基也会增大。
Multi Head Attention的过程就是先将Q,K,V映射到不同的子空间当中,再对不同的子空间做Attention,然后将结果联合起来,再通过一层全连接网络得到最后结果。
$$
MultiHead(Q,K,V) = Concat(head_1, head_2…)W^o
\\
where\ head_i = Attention(QW^q,KW^k,VW^v)
$$
其中, $W^q$,$W^k$,$W^v$的第二维度为各自初始维度d除以head数。
Position-wise Feed Forward Network
有点类似kernel size为1的卷积。对每个位置上的深度向量进行计算。
Position Encoding
由于Attention机制,不能捕捉位置信息,需要将位置信息编码到输入向量当中。有相对编码和绝对编码两种方式。
相对编码
相对编码是固定的,直接通过三角函数计算得到:
$$
PE(pos, 2i) = sin(pos/10000^{2i/d_{model}})
$$
$$
PE(pos, 2i+1)=cos(pos/10000^{2i/d_{model}})
$$
pos是位置编号,i是维度向量中的位置。之所以选择三角函数,因为对于PE(pos+k),可以很容易通过PE(pos) 线性变换得到。
绝对位置编码
绝对位置编码比较简单,直接随机初始化一个embedding矩阵,直接在训练当中学习得到。
二者比较
论文上说,基于机器翻译的实验来说,二者性能上几乎没有区别。然后,选择了相对位置编码,因为作者认为,模型可以在位置长度超出训练集case的情况下,得到一个比较合适的位置向量。
Mask机制
由于这边使用Attention,采用的是定长的结构,所以一般来说,会设一个最大长度,那么训练集当中会出现很多pad。期望的是在输入的时候,能够通过mask机制,将pad的向量在注意力机制中的权重为0。实现方式为修改attention权重矩阵,将mask的权重设置为一个超小的负数,使得算softmax时权重很小。